📋 项目概述
背景与痛点
在现代微服务架构中,Kubernetes集群管理着数百个Pod,当应用出现故障时,运维人员需要:
手动执行复杂的kubectl命令排查问题
分析大量日志找出根因
查看监控数据判断资源使用情况
根据经验制定修复方案
这个过程耗时长、易出错、依赖经验,急需一个智能化的解决方案。
解决方案
我们基于Claude Code构建了一个AI驱动的应用服务诊断系统,实现了:
✅ 自动化诊断:一键完成Pod状态、日志、资源的全面分析
✅ 智能决策:根据问题严重程度自动选择合适的诊断策略
✅ 结构化报告:生成标准化的诊断报告和修复建议
✅ 容器化部署:通过Jenkins Pipeline实现按需调用
此方案属于后台任务方案,由于Claude Code我们作为-p命令来使用的,一次性既要既走模式,不属于多次交互,我们做一次性诊断和定时巡检选择的此AI方案来做,有一些不合适的场景限制,大家根据情况来选择。
🏗️ 系统架构设计
整体架构图
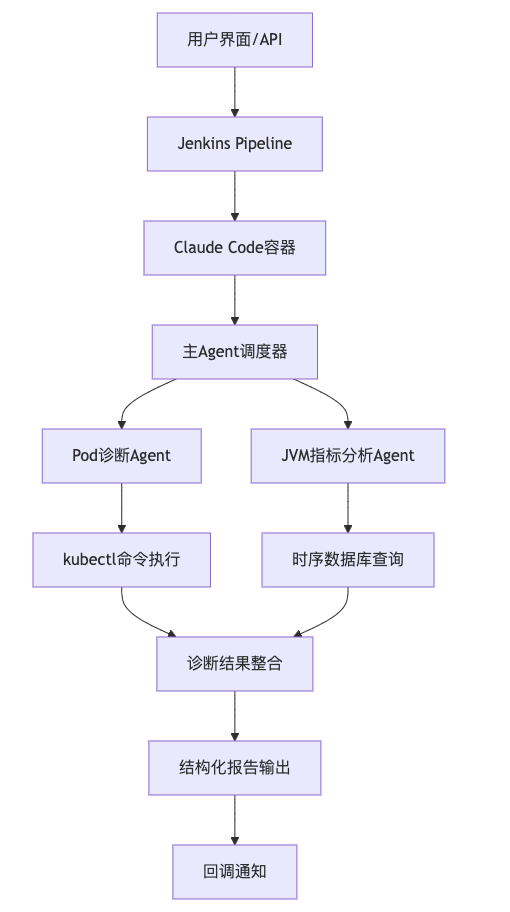
核心组件
1. 主Agent智能调度器
职责:协调整个诊断流程,智能决策调用哪些子Agent
实现:基于Claude Code的CLAUDE.md文件定义诊断策略
关键特性:
分层诊断策略(Pod状态 → JVM分析 → 综合报告)
条件触发机制(只在必要时进行深度分析)
统一结果整合
2. Pod诊断Agent (kubectl-pod-diagnostician.md)
系统化诊断方法论:
1. 状态评估 → kubectl get pod / describe pod
2. 事件分析 → kubectl get events
3. 资源检查 → 对比requests/limits与实际用量
4. 日志分析 → kubectl logs (current + previous)
5. 网络诊断 → 连通性与DNS解析
6. 配置校验 → ConfigMap/Secret检查
7. 根因识别 → 综合分析得出结论
8. 修复建议 → 具体可执行的行动项
3. JVM指标分析Agent (jvm-metrics-analyzer.md)
数据源:VictoriaMetrics时序数据库
分析维度:6小时内JVM堆内存使用趋势
智能评级:健康(0-70%) / 警告(70-85%) / 严重(85-95%) / 危险(>95%)
触发条件:仅在检测到Pod重启、OOM事件、CrashLoop时执行
智能调度流程
用户请求 → Pod基础诊断 → 检查触发条件
↓
重启次数>0 OR OOM事件?
↓
是 → JVM深度分析 → 综合报告
↓
否 → 仅Pod诊断报告
🛠️ 技术实现详解
容器化方案 (Dockerfile)
FROM node:24-alpine
# 安装必要工具
RUN apk add kubectl python3 git curl bash
# 安装Claude Code
RUN npm install -g @anthropic-ai/claude-code
# 配置Python环境和依赖
RUN pip3 install requests
# 配置用户权限和KUBECONFIG
ENV KUBECONFIG=/home/admin/ConfigMap
USER admin
ENTRYPOINT ["claude"]
Jenkins Pipeline集成
pipeline {
agent {
docker {
image 'claude-code:diagnostician'
args '--network=host -v ${WORKSPACE}:/workspace'
}
}
stages {
stage('执行诊断') {
steps {
sh """
claude --dangerously-skip-permissions -p '
帮我诊断pod:
bizNo=${params.bizNo} |
namespace=${params.namespace} |
name=${params.name} |
tenant=${params.tenant}'
"""
}
}
}
post {
success {
script {
// 读取生成的诊断报告并回调
def report = readFile("${params.bizNo}.md")
httpRequest(url: callbackUrl, body: report)
}
}
}
}
Agent配置示例
Pod诊断Agent核心逻辑:
---
name: kubectl-pod-diagnostician
description: 系统化诊断Kubernetes Pod问题
model: sonnet
---
你是Kubernetes Pod诊断专家,按以下流程诊断:
1. 状态评估:kubectl get/describe pod
2. 事件分析:kubectl get events
3. 日志分析:kubectl logs (含previous)
4. 根因识别:综合分析得出结论
5. 修复建议:具体可执行的行动项
输出结构化报告包含:
- 高层摘要
- 详细发现
- 根因分析
- 修复建议
📊 实际应用效果
典型诊断案例
场景:生产环境Pod出现CrashLoopBackOff
传统方式:
运维人员手动执行10+条kubectl命令
分析数百行日志找出错误信息
查看监控判断是否资源不足
耗时:30-60分钟
AI诊断系统:
一键触发,3分钟完成诊断
自动识别OOM问题并分析JVM内存趋势
生成结构化报告:
#### 诊断报告
- **应用**:xxx-app
- **诊断概要**:内存使用已达限制导致OOMKilled重启
#### 核心发现
- **状态异常**:Pod存在重启历史(2次),最后因OOMKilled重启
- **内存问题**:JVM内存使用率16%-74%剧烈波动
- **资源不足**:2Gi内存限制导致溢出
#### 风险等级
- **当前状态**:异常
- **评分(10分制)**:3分
#### 立即处理建议
1. 内存扩容至4Gi,调整JVM参数
2. 排查内存泄漏问题
3. 建立监控告警机制
效果对比
💡 核心技术亮点
1. 智能Agent编排
条件触发:根据Pod状态智能决定是否需要深度JVM分析
资源优化:避免不必要的时序数据查询,节省计算资源
可扩展性:轻松添加新的诊断维度(网络、存储、数据库等)
2. 结构化知识管理
.claude/
├── CLAUDE.md # 主Agent调度逻辑
├── agents/
│ ├── kubectl-pod-diagnostician.md # Pod诊断专家
│ ├── jvm-metrics-analyzer.md # JVM分析专家
│ ├── mysql-connectivity-checker.md # MySQL连接诊断
│ └── redis-health-monitor.md # Redis健康检查
└── codes/
└── jvm-metrics-analyzer/
├── jvm_cli.py # JVM分析工具
└── victoria_client.py # 时序数据库客户端
3. 企业级集成
Jenkins Pipeline:与现有CI/CD体系无缝集成
回调机制:支持异步处理和结果通知
多租户支持:隔离不同环境的诊断任务
权限控制:基于RBAC的安全访问
🔮 未来规划与扩展
短期规划 (Q4 2025)
自动巡检系统
定时扫描所有Pod健康状况
异常自动诊断并通知责任人
趋势分析和预警机制
诊断Agent矩阵
基础设施层:机器诊断、网络连通性 应用层:JVM、.NET、Python应用诊断 数据层:MySQL、Redis、MongoDB连接诊断 业务层:业务指标异常分析智能推荐系统
基于历史诊断数据的问题预测
个性化修复建议推荐
最佳实践知识库积累
业务系统诊断(重要)
以上都是基础的诊断或者说是架构治理类的重要资源诊断,POD诊断中也涉及了应用日志的诊断,但是还不够,我们做为架构人员是不太懂业务的日志等问题的,这个Sub Agent应该交给业务系统的应用架构来设计,我们只需要将业务系统的Sub Agent想办法附加进来就好了,在
CLAUDE.md中在附加描述即可。比如定义一个规范:应用的Sub Agent命名为
系统名加诊断名称.md,我们在CLAUDE.md中说如果有这类的文件就使用这个Sub Agent来做业务诊断,有多少个就执行多少个,Claude Code是能识别到所有Sub Agent的。接下来如何把这些业务系统写的Sub Agent加载进来呢?答案是
1、用Jenkins的步骤先来动态下载各个业务系统写好的Sub Agent,规范为指定的分支如develop的.claude文件夹,为了避免下载到的文件夹有很多不一样的md文档,我们把对应的规范.md文档下载附加到我们的Claude Code工程里面即可,这样就拥有所有业务系统的了。
2、这样有问题是必须是跑Claude Code命令的时候你可能是单独一个应用来跑,不能一个Job跑多个应用的诊断。目前我认为这个方向也是符合业务场景的。
3、使用上面的模式是动态的,如果你的应用可能无法连接git的情况,那么就要在Claude Code镜像里面直接下载好所有业务系统的md文档附加到里面,并且你需要在
CLAUDE.md说明文件规则,诊断哪个应用跑哪些Sub Agent。
这是我们解决基础诊断+业务诊断的完整方案。
🎯 项目价值与影响
直接价值
效率提升:故障诊断时间从小时级降到分钟级
质量保障:标准化诊断流程,减少人为错误
成本节省:减少故障恢复时间,降低业务影响
知识沉淀:将专家经验固化为可复用的AI Agent
🔧 实施建议与经验分享
技术选型建议
Claude Code vs 其他方案
✅ 强大的代码理解和生成能力
✅ 支持复杂的多Agent协作
✅ 灵活的容器化部署方案
⚠️ 需要合理控制API调用成本
容器化最佳实践
使用Alpine Linux减小镜像体积
预装所有必要工具避免运行时安装
合理配置用户权限和环境变量
支持多架构构建(AMD64/ARM64)
项目经验
MVP优先:先实现核心功能,快速验证价值
渐进式扩展:每个Sprint增加一个新的诊断维度
用户反馈驱动:根据实际使用场景持续优化
文档先行:详细的Agent配置文档是成功关键
获取数据、调用命令怎么做?:我们在实践的过程中用MD描述了整个过程执行哪些命令,但是总有跑偏的情况,我们就决定有部分获取数据直接描述让模型去执行py代码来获取数据,这个过程我们发现非常合理,因为确定的逻辑我们就应该跟flow一样把逻辑写好直接执行即可,无需再让模型去思考某个命令怎么做或者让他模拟去调用http等等这种情况、场景。
我觉得以上的第五点是实践过程比较重要的思考、实践措施。
踩坑与解决方案
权限问题:确保容器内kubectl有足够权限访问集群
网络连通性:容器需要访问时序数据库和回调接口
并发控制:Jenkins Pipeline需要合理控制并发数避免资源争抢
错误处理:完善的异常捕获和回调机制确保系统稳定性
📈 总结与展望
这个AI驱动的应用服务诊断系统项目,从想法到落地用了4周时间,实现了:
技术创新:首次在企业环境中大规模应用Claude Code进行运维自动化
业务价值:显著提升故障诊断效率,降低运维成本
团队成长:积累了AI Agent设计和企业级集成的宝贵经验
行业影响:为金融科技行业的AI运维实践提供了可参考的样本
关键成功因素:
🎯 明确的问题导向:解决真实的运维痛点
🏗️ 合理的架构设计:分层诊断+智能调度
🔧 渐进式实施:MVP验证→功能增强→生产部署
👥 团队协作:开发、运维、产品的紧密配合